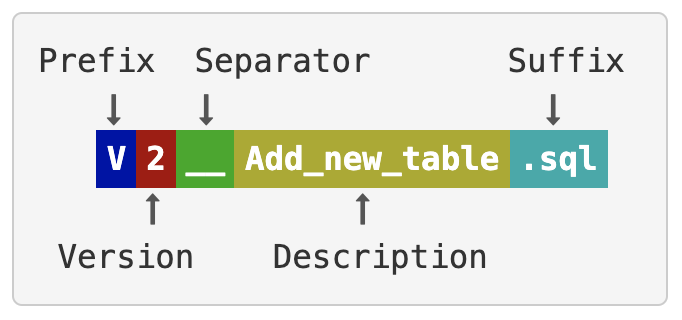
db-schemachange is a simple, lightweight python based tool to manage database objects for Databricks, Snowflake, MySQL, Postgres, SQL Server, and Oracle. It
follows an Imperative-style approach to Database Change Management (DCM) and was inspired by
the Flyway database migration tool. When combined with a version control system and a CI/CD
tool, database changes can be approved and deployed through a pipeline using modern software delivery practices. As such
schemachange plays a critical role in enabling Database (or Data) DevOps.