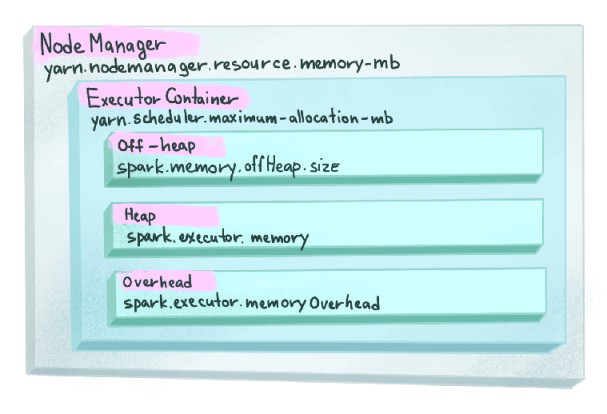
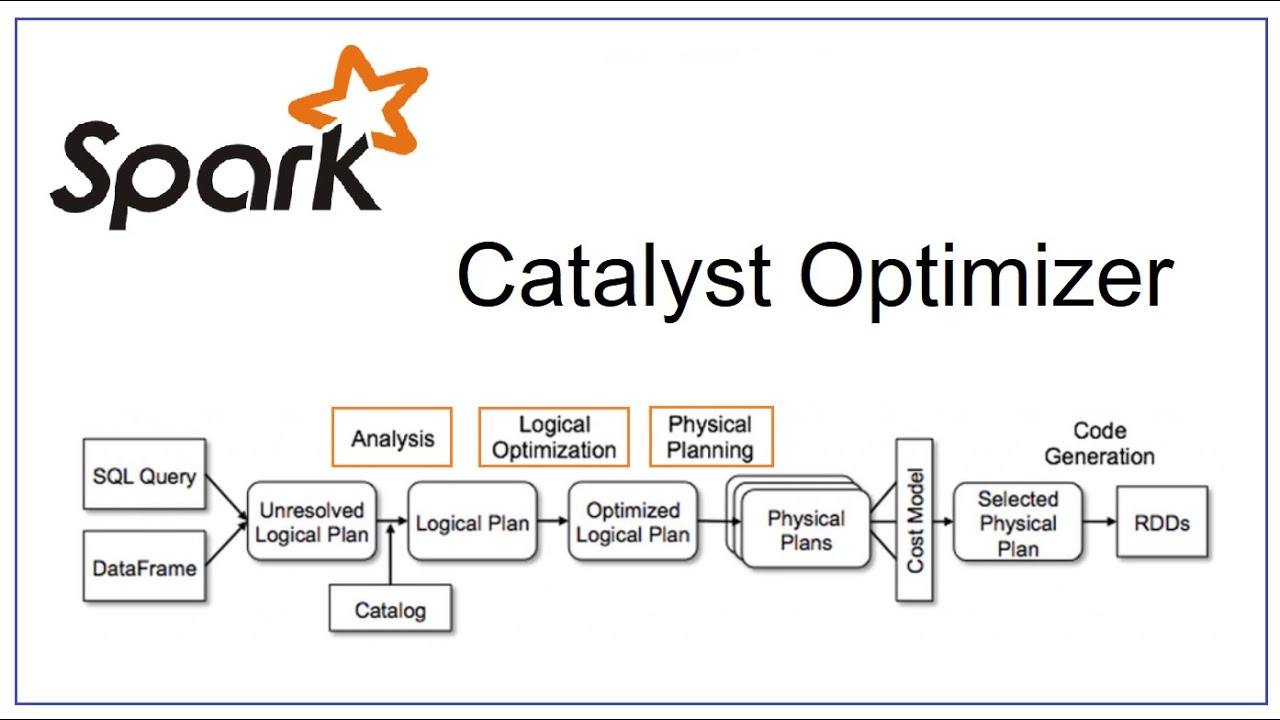
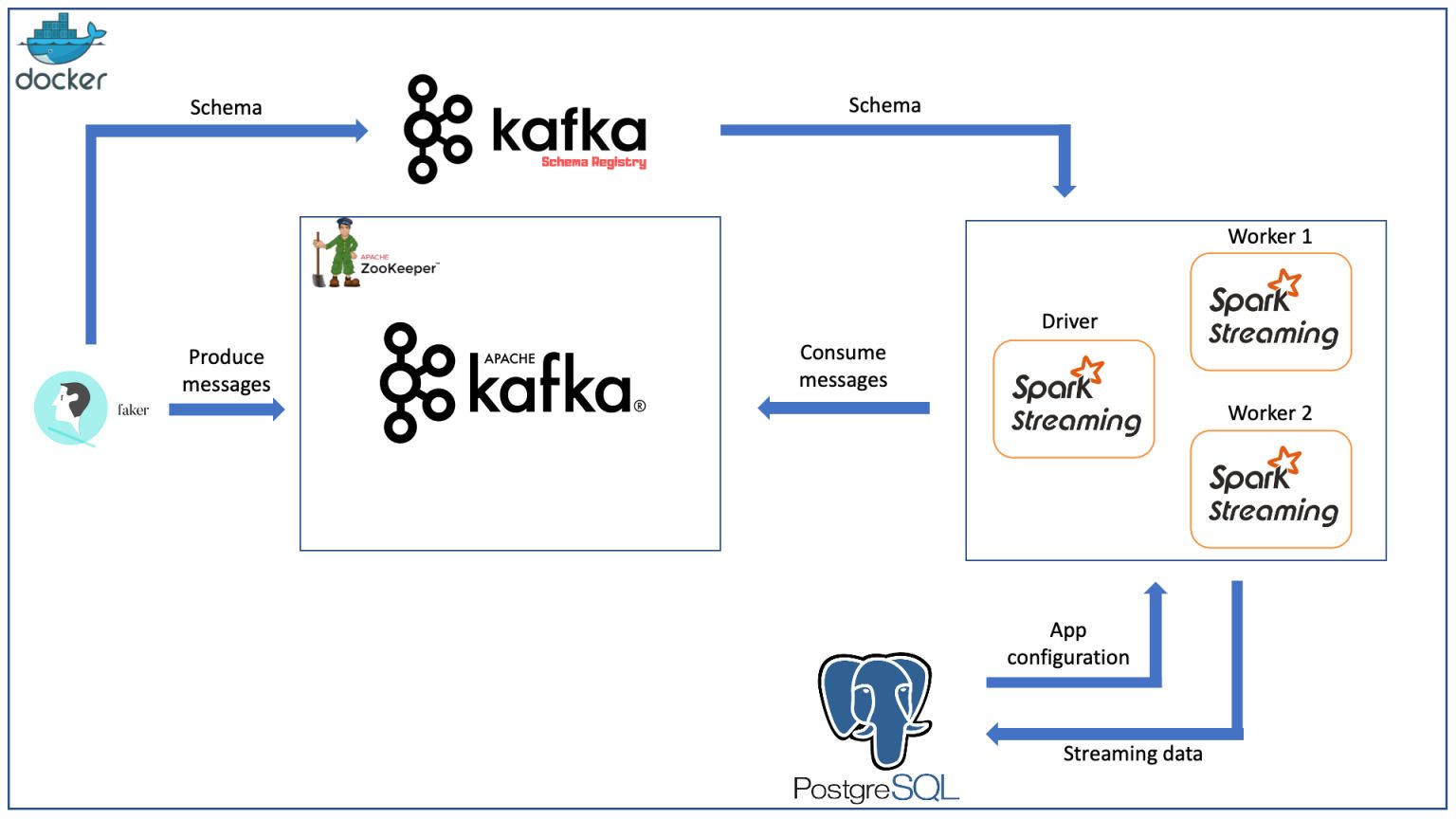
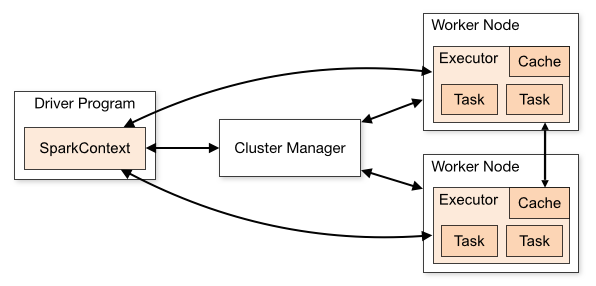
I have participated in fews technical interviews and have discussed with people topics around data engineering and things they have done in the past. Most of them are familiar with Apache Spark, obviously, one of the most adopted frameworks for big data processing. What I have been asked and what I often ask them is simple concepts around RDD, Dataframe, and Dataset and the differences between them. It sounds quite fundamental, right? Not really. If we have more closer look at them, there are lots of interesting things that can help us understand and choose which is the best suited for our project.