Tiếp đây sẽ là loạt bài viết về đại số tuyến tính mình đã học lại khi đọc quyển Mathematics for Machine Learning trong thời gian học về Machine Learning và AI. Đây là phần thứ nhất trong loạt bài này.
Hệ phương trình tuyến tính là tập các phương trình tuyến tính với cùng những biến số, cấp 2 chúng ta đã giải chán chê phương trình này, thậm chí còn phải làm các hệ phương trình khó nhằn hơn chứa cả biến bậc 2, bậc 3,... Giờ đây, trở lại với đại số tuyến tính, ta có thể mô hình hệ phương trình tuyến tính bậc một với tích của ma trận và véc-tơ tương ứng.
Ví dụ ta có một hệ phương trình đơn giản sau
⎩⎨⎧x1+8x3−4x4=42x2+2x3+12x4=8
Sẽ được viết dưới dạng tích ma trận và véc-tơ biến số như sau
Nhìn vào phương trình trên, ta có được một nghiệm cho Ax=0 là λ1[82−10]T.
Tương tự như trên, ta tìm thêm được một nghiệm cho Ax=0 nữa là λ2[−4120−1]T.
Phương trình Ax=0 chỉ có 2 nghiệm, tại sao lại như vậy thì bên dưới mình sẽ nói sau.
Như vậy, hệ phương trình có nghiệm chung là
Những hàng chỉ chứa 0 sẽ ở đáy ma trận. Những hàng chứa ít nhất 1 số khác không sẽ nằm trên các hàng chứa toàn 0.
Các phần tử pivot của mỗi hàng luôn ở phía bên phải của các phần tử pivot ở các hàng bên trên.
Các biến ứng với các phần tử pivot là các basic variables, các biến còn lại là free variables. Do vậy mà ở Mục 1.1 phương trình Ax=0 chỉ có hai nghiệm, tại chỉ có 2 biến là free variables (tức là các biến ứng với các phần tử không là phần tử pivot).
Với hệ phương trình tuyến tính Ax=b, để tính toán một nghiệm riêng, ta biểu diễn các b=∑i=1pλipi với pi là các pivot columns, chúng ta thường bắt đầu ước lượng các giá trị λi với các pivot columns từ phải sang trái.
Một ma trận ở dạng bậc thang tối giản nếu
Nó là một ma trận bậc thang.
Các phần tử pivot đều bằng 1.
Phần tử pivot là phần tử duy nhất khác 0 tại pivot column đó.
Việc tính toán nghiệm Ax=0 sẽ dễ dàng hơn rất nhiều nếu ma trận biểu diễn hệ phương trình tuyến tính ở dạng bậc thang tối giản
Là một thuật toán biểu diễn các phép biến đổi triệt tiêu giữa các hàng để đưa ma trận biểu diễn hệ phương trình tuyến tính về dạng ma trận bậc thang tối giản.
Để tính toán nghiệm của Ax=0 trong ma trận bậc thang tối giản, ta biểu diễn các pivot column bằng tổng các cấp số của các pivot columns ở bên trái của chúng.
Với ma trận A ở trên, ta sẽ chêm các hàng gồm toàn 0 và chỉ một số −1 vào giữa các hàng của ma trận bậc thang tối giản, để tạo nên ma trận mới có đường chéo chính gồm toàn −1 và 1 như dưới đây.
A⇝⎣⎡100003−100000100−40−3−1000001⎦⎤
Từ đó, các cột chứa giá trị −1 tại các vị trí trên đường chéo chính của ma trận sẽ là nghiệm của phương trình Ax=0.
Có một số thuật toán thông dụng để giải hệ phương trình tuyến tính phức tạp
Sử dụng thuật toán hồi quy tuyến tính (linear regression), thuật toán này thường áp dụng vào các bài toán mà ta chỉ có thể tính xấp xỉ nghiệm của phương trình.
Normal equation, thuật toán này tính chính xác nghiệm của hệ phương trình, nhưng số lượng tính toán rất nhiều nên không thể sử dụng với các trường hợp số lượng biến nhiều. Phương pháp này được thể hiện dưới đây
Ax=b⇔ATAx=ATb⇔x=(ATA)−1ATb
Việc phải nhân ma trận và tính toán nghịch đảo khiến phương pháp này có độ phức tập là Θ(n3).
Cho một tập G với phép toán ⊗:G×G→G được định nghĩa trên G thì G:=(G,⊗) được gọi là một nhóm nếu thỏa mãn các tính chất
Tính đóng gói của G trong phép ⊗: ∀x,y∈G thì x⊗y∈G.
Tính kết hợp: ∀x,y,z∈G thì (x⊗y)⊗z=x⊗(y⊗z).
Tồn tại phần tử đơn vị: ∃e∈G,∀x∈G thỏa mãn x⊗e=x và e⊗x=x.
Tồn tại phần tử nghịch đảo: ∀x∈G,∃y∈G thỏa mãn x⊗y=e và y⊗x=e.
Nếu nhóm có thêm tính chất giao hoán ∀x,y∈G:x⊗y=y⊗x thì nhóm đó được gọi là nhóm Abelian.
Một nhóm các ma trận khả nghịch A∈Rn×n với phép toán nhân ma trận được gọi là một General Linear Group. Tuy nhiên, phép nhân ma trận không có tính chất giao hoán nên nhóm này không phải là một nhóm Abelian.
Với V=(V,+,⋅) là một không gian véc-tơ và U⊆V,U=∅ thì U=(U,+,⋅) được gọi là không gian véc-tơ con của V nếu U là một không gian véc-tơ cùng với các phép toán + và ⋅ ứng với U×U và R×U. Kí hiệu U⊆V thể hiện U là một không gian véc-tơ con của V.
Nếu U là một không gian véc-tơ con của V, U sẽ thừa hưởng tất cả các tính chất của V. Để chứng minh U là một không gian véc-tơ con của V, chúng ta vẫn phải chỉ ra được
U=∅ hay 0∈U.
Tính đóng gói của U: ∀λ∈R,∀x∈U:λx∈U và ∀x,y∈U:x+y∈U.
Nếu có một tổ hợp tuyến tính không tầm thường thỏa mãn 0=∑i=1k=λixi với ít nhất một giá trị λi=0 thì các véc-tơ x1,x2,...,xk được gọi là phụ thuộc tuyến tính.
Nếu mà biểu thức trên chỉ tồn tại nghiệm tầm thường λ1=λ2=...=λk=0 thì các véc-tơ x1,x2,...,xk là độc lập tuyến tính.
Một số tính chất cho các véc-tơ kiểu này là
k véc-tơ trên hoặc là độc lập tuyến tính, hoặc là phụ thuộc tuyến tính, chứ không có loại khác.
Nếu ít nhất một trong số các véc-tơ x1,x2,...,xk là véc-tơ 0 thì chúng sẽ phụ thuộc tuyến tính. Tính chất này cũng tương đương với việc có 2 véc-tơ giống nhau trong tập k véc-tơ trên.
Tập các véc-tơ trên là phụ thuộc tuyến tính nếu như một trong số các véc-tơ đó có thể được biểu diễn dưới dạng tổ hợp tuyến tính của các véc-tơ còn lại.
Ta viết tất cả véc-tơ thành các cột của một ma trận A, sau đó biểu diễn phép khử Gaussian, ta được các pivot columns sẽ độc lập tuyến tính với các véc-tơ ở bên trái của véc-tơ đó, còn các cột không phải pivot columns sẽ có thể được biểu diễn dưới dạng một tổ hợp tuyến tính của các pivot columns ở bên trái của nó. Nếu tất cả các cột đều là pivot columns thì tất cả các véc-tơ đó là độc lập tuyến tính, còn không thì chúng sẽ là phụ thuộc tuyến tính.
Cho một không gian véc-tơ V=(V,+,⋅) và một tập các véc-tơ A=x1,x2,...,xk⊆V . Nếu mỗi véc-tơ v∈V đều có thể biểu diễn là một tổ hợp tuyến tính của x1,x2,...,xk, thì A được gọi là hệ sinh của V. Tập tất cả tổ hợp tuyến tính của A được gọi là một span của A. Nếu A span không gian véc-tơ V, chúng ta viết V=span[A] hoặc V=span[x1,x2,...,xk].
Cho một không gian véc-tơ V=(V,+,⋅) và hệ sinh A⊆V, A được gọi là hệ sinh nhỏ nhất nếu không tồn tại một hệ sinh nhỏ hơn nào khác mà A~⊊A⊆V span không gian véc-tơ V. Tất cả hệ sinh độc lập tuyến tính của không gian véc-tơ V là nhỏ nhất và được gọi là cơ sở của V.
Với V=(V,+,⋅) là một không gian véc-tơ và B⊆V và B=∅. Tất cả mệnh đề sau là tương đương
B là một cơ sở của V.
B là hệ sinh nhỏ nhất.
B là một tập gồm số véc-tơ độc lập tuyến tính lớn nhất của V.
Tất cả v∈V là một tổ hợp tuyến tính của các véc-tơ trong B và tất cả tổ hợp tuyến tính là duy nhất. Nếu x=∑i=1kλibi=∑i=1kψibi thì λi=ψi.
Ta có ví dụ về hệ sinh chuẩn tắc của R3 là
B=⎣⎡100⎦⎤,⎣⎡010⎦⎤,⎣⎡001⎦⎤
Một số kết luận được rút ra như sau
Tất cả cơ sở đều có số các phần tử bằng nhau. Số chiều của một không gian = số các hướng độc lập nhau trong không gian đó. Số chiều của một không gian véc-tơ sẽ là số véc-tơ trong hệ cơ sở của không gian véc-tơ đó dim(V) = số véc-tơ trong cơ sở của nó.
Nếu U⊆V là một không gian véc-tơ con của V, thì dim(U) ≤ dim(V), dim(U) = dim(V) khi và chỉ khi U=V.
Một cơ sở của không gian véc-tơ con U=span[x1,x2,...,xk]⊆Rm có thể được tìm bằng cách sau
Viết các véc-tơ x1,x2,...,xk dưới dạng một cột của một ma trận A.
Biến đổi A về dạng ma trận bậc thang tối giản.
Các véc-tơ liên kết với các pivot columns là cơ sở của không gian véc-tơ con U.
Hai không gian véc-tơ thực V,W, một ánh xạ Φ:V→W bảo toàn cấu trúc các không gian véc-tơ nếu
Φ(x+y)=Φ(x)+Φ(y)Φ(λx)=λΦ(x)
Với tất cả x,y∈V và λ∈R.
Ánh xạ tuyến tính: Với các không gian véc-tơ V,W, một ánh xạ Φ:V→W được gọi là một ánh xạ tuyến tính nếu ∀x,y∈V,∀λ,ψ∈R:Φ(λx+ψy)=λΦ(x)+ψΦ(y). Ánh xạ tuyến tính có thể được biểu diễn dạng ma trận, về phần này mình sẽ nói ở dưới.
Hai không gian véc-tơ V và W có chiều hữu hạn được gọi là đẳng cấu khi và chỉ khi dim(V) = dim(W). Do vậy, tồn tại một song ánh giữa 2 không gian véc-tơ cùng số chiều. Tức là, hai không gian véc-tơ có số chiều bằng nhau là hai thứ giống nhau, khi mà nó có thể được biến đổi sang nhau mà không mất mát thông tin gì.
Ta có một số tính chất của ánh xạ tuyến tính
Nếu ánh xạ tuyến tính Φ:V→W và ψ:W→X, phép ánh xạ ψ∘Φ:V→X cũng là một ánh xạ tuyến tính.
Nếu Φ:V→W là một đẳng cấu thì Φ−1:W→V cũng là một đẳng cấu.
Nếu Φ:V→W, ψ:V→W là ánh xạ tuyến tính thì Φ+ψ,λΦ với λ∈R cũng là các ánh xạ tuyến tính.
Xét một không gian véc-tơ V với cơ sở là B=(b1,b2,...,bn). Với mọi véc-tơ x∈V, ta có một tổ hợp tuyến tính duy nhất là
x=λ1b1+λ2b2+...+λnbn
Thì λ1,λ2,...,λn được gọi là tọa độ của x đối với cơ sở B.
λ=⎣⎡λ1λ2⋮λn⎦⎤ được gói là véc-tơ tọa độ của x đối với cơ sở B. Do vậy, với một véc-tơ với các cơ sở khác nhau thì sẽ có tọa độ là khác nhau.
Xét các không gian véc-tơ V và W với các cơ sở tương ứng là B=(b1,b2,...,bn) và C=(c1,c2,...,cm)và một ánh xạ tuyến tính Φ:V→W. Với j∈1,2,...,n
Φ(bj)=λ1jc1+λ1jc2+...+λmjcm=∑i=1mλijci
là một biểu diễn duy nhất của Φ(bj) với cơ sở C. Chúng ta gọi ma trận AΦ kích thước m×n với AΦ(i,j)=λij là ma trận biến đổi của Φ ứng với cơ sở B của không gian véc-tơ V và cơ sở C của không gian véc-tơ W.
Tọa độ của Φ(bj) ứng với cơ sở C của W là cột thứ jth của ma trận AΦ.
Do đó, nếu x^ là véc-tơ tọa độ của x∈V ứng với cơ sở B và y^ là véc-tơ tọa độ của y=Φ(x)∈W ứng với cơ sở C. Ta có
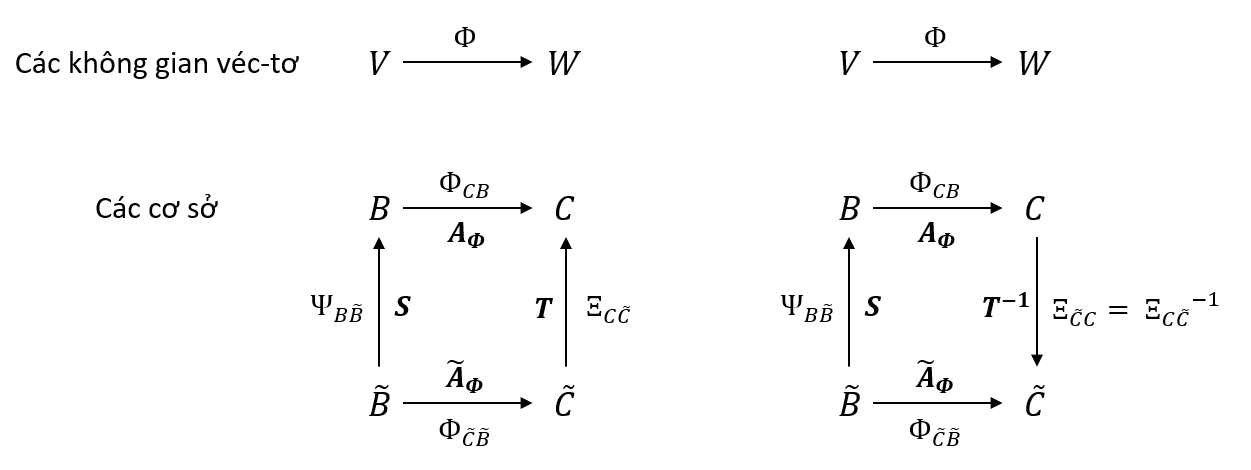
B=(b1,b2,...,bn) và B~=(b1~,b2~,...,bn~) của V.
C=(c1,c2,...,cn) và C~=(c1~,c2~,...,cn~) của W.
AΦ∈Rm×n là ma trận biến đổi của ánh xạ tuyến tính Φ:V→W ứng với cơ sở B và C.
AΦ~∈Rm×n là ma trận biến đổi của ánh xạ tuyến tính Φ:V→W ứng với cơ sở B~ và C~.
Bằng việc chuyển đổi cơ sở và các biểu diễn của các véc-tơ, các ma trận biến đổi ứng với các cơ sở mới có thể ở dạng rất đơn giản và dễ dàng thực hiện các bước tính toán trung gian.
Với 2 ma trận biến đổi như ở phần trên, tương quan giữa chúng được biểu diễn như sau
AΦ~=T−1AϕS
Với S∈Rn×n là ma trận biến đổi của phép ánh xạ đơn vị liên kết tọa độ của véc-tơ ứng với cơ sở B~ lên tọa độ ứng với cơ sở B.
Với T∈Rm×m là ma trận biến đổi của phép ánh xạ đơn vị liên kết tọa độ của véc-tơ ứng với cơ sở C~ lên tọa độ ứng với cơ sở C.
(Phần chứng minh chi tiết bạn có thể truy cập link sách mà mình để ở trên)
Như vậy, một phép biến đổi cơ sở trong V (cơ sở B được thay thế bằng cơ sở B~) và W (cơ sở C được thay thế bằng cơ sở C~), ma trận biến đổi AΦ của phép ánh xạ tuyến tính Φ:V→W được thay thế bởi ma trận biến đổi tương đương AΦ~.
Nhìn vào hình trên, ta thấy được
ΦB~C~=ΞC~C∘ΦCB∘ψBB~=ΞCC~−1∘ΦCB∘ψBB~
Với ψBB~=idV và ΞC~C=idW là các ánh xạ đơn vị ánh xạ các véc-tơ lên chính chúng, nhưng mà ứng với các cơ sở khác nhau.
Sau đây, mình đưa ra 2 khái niệm sau về ma trận
Tương đương: 2 ma trận A,A~∈Rm×n là tương đương nếu tồn tại hai ma trận khả ngịch S∈Rn×n và T∈Rm×m thỏa mãn A~=T−1AS.
Đồng dạng: 2 ma trận A,A~∈Rn×n là đồng dạng nếu tồn tại ma trận khả ngịch S∈Rn×n thỏa mãn A~=S−1AS.
Cuối cùng, xét các không gian véc-tơ V,W,X. Các ánh xạ tuyến tính Φ:V→W với ma trận biến đổi là AΦ và ψ:W→X với ma trận biến đổi là Aψ, ánh xạ ψ∘Φ:V→X cũng là ánh xạ tuyến tính với ma trận biến đổi là Aψ∘Φ=AψAΦ. Chứng minh như sau
Với V là một không gian véc-tơ, x0∈V và U⊆V là một không gian véc-tơ. Nếu tập con
L=x0+U:=x0+u:u∈U=v∈V∣∃u∈U:v=x0+u⊆V
được gọi là một không gian véc-tơ Affine con. U được gọi là không gian hướng và x0 được gọi là support point.
Định nghĩa của không gian véc-tơ Affine sẽ không chứa 0 nếu x0∈/U. Vì thế mà không gian véc-tơ Affine không phải là một không gian véc-tơ con của V với x0∈/U.
Cho 2 không gian véc-tơ Affine L=x0+U và L~=x0~+U~ của không gian véc-tơ V. L∈L~ khi và chỉ khi U∈U~ và x0−x0~∈U~.
Cho một không gian véc-tơ Affine k chiều L=x0+U của V. Nếu (b1,b2,...,bk) là một cơ sở của U, thì mỗi x∈L có thể được biểu diễn duy nhất dưới dạng
x=x0+λ1b1+λ2b2+...+λkbk
Biểu diễn này được gọi là phương trình tham số của L với các véc-tơ hướng b1,b2,...,bk và các tham số λ1,λ2,...,λk.