
Indexing is a method to make queries faster, which is a very important part of improving performance. For large data tables, precise indexing will increase the query speed as a whole, however, this is often not taken into account in the table design process. This article talks about the types of indexes and how to properly index them.

Types of index
There are many types of indexes designed for different purposes. Remember, indexes are implemented at the storage engine layer, not at the server layer, so they behave differently in different storage engines. The types of indexes in this article are mainly about indexes in InnoDB.
B-tree index
B-tree index uses a balanced tree to store its data, almost all MySQL storage engines support this type of index (or its variant), for example, the NDB Cluster storage engine uses the data structure T-tree for indexing, InnoDB uses B+ tree,...
In B-tree, all values are sorted, and leaves are equally spaced from the root of the tree. Below figure is a description of the B-tree data structure.
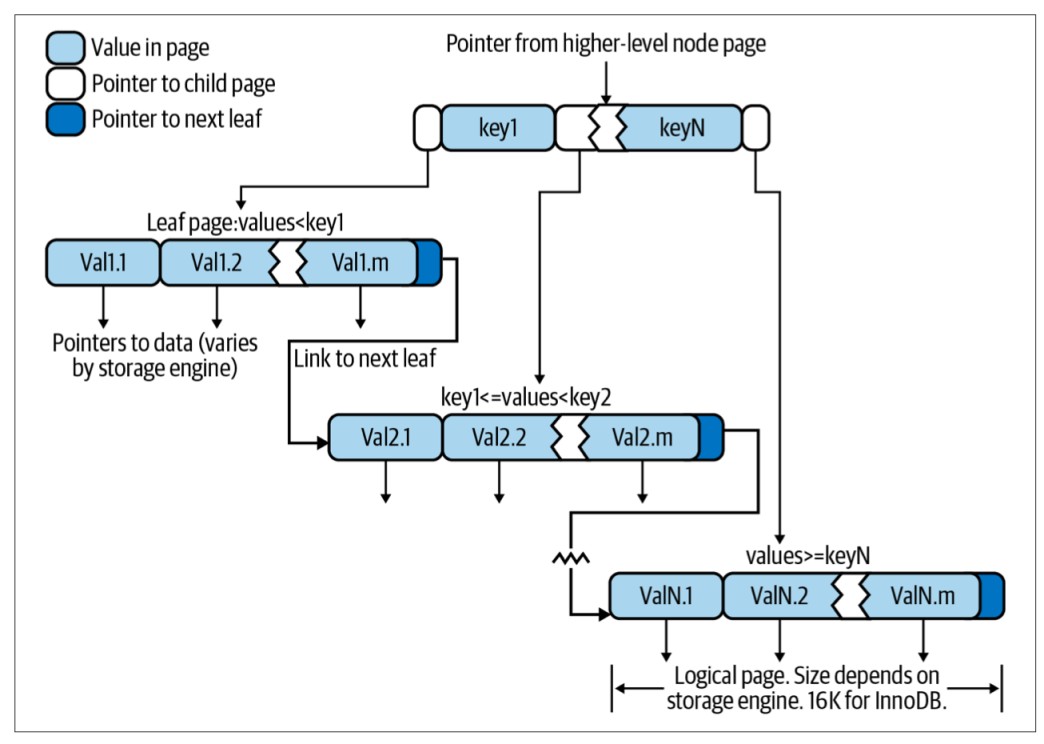
B-trees provide the ability to search, access sequential data, insert and delete with logarithmic time complexity . At the root node, there will be pointers to the child nodes, when we query, the storage engine will know the appropriate subnode branch to browse by looking at the values in the node pages, containing the upper and lower threshold information, child nodes in that page. At the leaf page layer, pointers point to data instead of other pages.
In the image above, we only see a node page and leaf pages. In fact, the B-tree has many layers of node pages between the root node and the leaf nodes, the size of the tree depends on the size of the indexed table.
Adaptive hash index
When index values are accessed with high frequency, InnoDB will build a hash index for them in memory on top of the B-tree index, making it possible to find this hash value very quickly and efficiently. This mode is automatic by InnoDB, however, you can still disable adaptive hash index if you want.
Types of query that are efficient with B-tree index
B-tree indexes work well with exact-value, range, or value-prefix query types. These queries are best when we use them on the leftmost column in the indexed set of columns.
CREATE TABLE People (
last_name varchar(50) not null,
first_name varchar(50) not null,
dob date not null,
KEY `idx_full_col` (last_name, first_name, dob)
) ENGINE=InnoDB;
- Exact match: when the columns in the index are queried to match a certain value, for example
WHERE last_name = 'lam' AND first_name = 'tran' AND dob = '1999-05-10'. This type of query will return results very quickly. - Match the leftmost column: for example, if we query to find people with
last_name = 'lam'. - Match the first part of the left most column: For example, when we find the person whose last_name starts with the letter 'L'.
- Match a range of values: when we need to get the set of people whose last_name is between 'anh' and 'lam'.
- Match the leftmost column and a range of the next column values: for example, when we need information about people last_name is 'lam' and first_name starts with 't'.
Drawbacks of B-tree index
- It won't really help when the query condition doesn't start with the leftmost column, nor is it good when the query finds people whose last_name ends with a specific letter.
- Queries that skip some columns also don't take full advantage of the index. For example when looking for people
last_name = 'lam' AND dob = '1999-05-10'with no condition on first_name. - Indexes of this type will not take advantage of the columns behind the range matching column. For example, the query people
last_name = 'lam' AND first_name LIKE 't%' AND dob = '1999-05-10'will only apply the index on the last_name and first_name columns. For columns with less distinct data, we can overcome this by enumerating all values instead of accessing the range of values.
Thus, the order of the columns in the index is really important, you need to consider the query goal of the application before indexing the columns.
Full-text index
The full-text index searches for keywords in the text string instead of comparing the field's value directly. It aids in searching rather than judging what type the data matches. When a column has a full-text index, we can still type a B-tree index on that column.
CREATE TABLE tutorial (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(200),
description TEXT,
FULLTEXT `idx_full_text` (title,description)
) ENGINE=InnoDB;
The full-text index is used by syntax MATCH() AGAINST() with the parameter of MATCH() are columns to search, separated by commas. The parameter of AGAINST() is a string to search and type of search to perform.
Types of full-text index
- Natural language search: this mode will interpret the search string as a phrase in natural human language. This mode does not count stopwords as well as words shorter than the minimum number of characters (default is 3 characters with InnoDB).
- Boolean search: interprets the search string using special query language rules. The string contains all the words to be searched, it can also contain special operators for advanced searches, such as a word that needs to appear in the string, or a word that is weighted heavier or lighter. Stop words will be ignored in this mode.
- Query expansion: is a variation of natural language search. The words in the most relevant rows returned will be added to the search string, and the search will be repeated. The query will return rows in the second search.
I won't go into each type in detail, because I rarely use the full-text index.
Benefits of indexing
Some benefits of indexing
- Index helps server save time for browsing and querying.
- Index helps the server avoid operations such as sorting data or creating temporary tables.
- Index turns random disk access into sequential access, improving read speed
Some criteria to evaluate index
- Index needs to arrange related rows, closer together.
- The sorted rows should be exactly what your application queries need.
- Index needs to contain all the columns that your application query filters.
Indexing strategies
Creating the right indexes will greatly improve your query speed, which in turn makes your application more responsive to users.
Prefix index for text field
Consider Index Selectivity is the ratio between the number of different column values / total records of the table. For columns with high Index Selectivity, indexing on these fields is very effective because MySQL will remove more records when filtering on those columns. For long text fields, we cannot index the whole column length because MySQL won't allow that, so we need to find a good enough prefix of that field to index and it will give us a good enough performance.
Try with the product data below, we list the top ten sellers that appear the most
select productVendor, count(1) c from `classicmodels`.`products_index`
group by productVendor
order by c desc
LIMIT 10;
+--------------------------------------------------+----+
| productVendor | c |
+--------------------------------------------------+----+
| Pressure and Safety Relief Valve | 10 |
| NEC United Solutions | 9 |
| SunGard Data Systems | 8 |
| Zhengzhou Esunny Information Technology Co.,Ltd. | 8 |
| Spring Support | 8 |
| Ball and Plug Valve | 7 |
| LSAW Pipe | 7 |
| Wood Mackenzie Ltd | 7 |
| Heat Recovery Steam Generator | 7 |
| Carbon Steel Flange | 7 |
+--------------------------------------------------+----+
Try to calculate the frequency of occurrence of length 3 prefix with the field productVendor
select LEFT(productVendor, 3), count(1) c from `classicmodels`.`products_index`
group by LEFT(productVendor, 3)
order by c desc
LIMIT 10;
+------------------------+----+
| LEFT(productVendor, 3) | c |
+------------------------+----+
| Sha | 44 |
| Car | 16 |
| Sun | 15 |
| Zhe | 13 |
| Gas | 12 |
| Sto | 11 |
| Pre | 11 |
| Col | 11 |
| She | 9 |
| Hea | 9 |
+------------------------+----+
We see that the frequency of occurrence of length 3 prefix is a lot more compare to full column values, which equates to fewer distinct values, which equates to a much smaller Index Selectivity. So prefix 3 is not a good choice
Let's calculate the Index Selectivity with various prefix lengths
select COUNT(DISTINCT LEFT(productVendor, 3))/COUNT(1) AS selectivity_3,
COUNT(DISTINCT LEFT(productVendor, 4))/COUNT(1) AS selectivity_4,
COUNT(DISTINCT LEFT(productVendor, 5))/COUNT(1) AS selectivity_5,
COUNT(DISTINCT LEFT(productVendor, 6))/COUNT(1) AS selectivity_6,
COUNT(DISTINCT LEFT(productVendor, 7))/COUNT(1) AS selectivity_7,
COUNT(DISTINCT LEFT(productVendor, 8))/COUNT(1) AS selectivity_8,
COUNT(DISTINCT LEFT(productVendor, 9))/COUNT(1) AS selectivity_9,
COUNT(DISTINCT LEFT(productVendor, 10))/COUNT(1) AS selectivity_10,
COUNT(DISTINCT LEFT(productVendor, 11))/COUNT(1) AS selectivity_11,
COUNT(DISTINCT productVendor)/COUNT(1) AS selectivity
from `classicmodels`.`products_index`;
+---------------+---------------+---------------+---------------+---------------+---------------+---------------+----------------+----------------+-------------+
| selectivity_3 | selectivity_4 | selectivity_5 | selectivity_6 | selectivity_7 | selectivity_8 | selectivity_9 | selectivity_10 | selectivity_11 | selectivity |
+---------------+---------------+---------------+---------------+---------------+---------------+---------------+----------------+----------------+-------------+
| 0.1982 | 0.2164 | 0.2218 | 0.2236 | 0.2236 | 0.2273 | 0.2309 | 0.2491 | 0.2509 | 0.2600 |
+---------------+---------------+---------------+---------------+---------------+---------------+---------------+----------------+----------------+-------------+
We see that the selectivity prefix 11 is very close to the column selectivity value, and is also quite suitable for long text fields like this column, so choosing prefix 11 will balance the size of the index as well as the speed of the query.
ALTER TABLE `classicmodels`.`products_index` ADD KEY (productVendor(11));
Index on multiple columns
Some mistakes when indexing is indexing each column separately, and creating indexes for all columns in the WHERE statement.
CREATE TABLE t (
c1 INT,
c2 INT,
c3 INT,
KEY(c1),
KEY(c2),
KEY(c3)
);
Separate indexes like the one above will usually not optimize performance very much in most situations, because then MySQL can use a tactic called index merge. Index merge will use all the indexes in the query, scan the indexes simultaneously, then merge the results again.
- Union index will be used for OR condition
- Intersection index will be used for AND condition
- Union of intersection index for the union of both 2
Here is an example query on 2 index fields but MySQL uses index merge
mysql> explain select * from `classicmodels`.`products_index` where productVendor = 'Infor Global Solutions' OR productScale = '1:10'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: products_index
partitions: NULL
type: index_merge
possible_keys: productVendor,productScale
key: productVendor,productScale
key_len: 14,12
ref: NULL
rows: 33
filtered: 100.00
Extra: Using sort_union(productVendor,productScale); Using where
Some considerations when query encounters index merge
- If the server intersects the index (AND condition on the indexes), it means that you can create an index containing all the columns related to each other, not each index for each column.
- If the server union index (OR condition on the indexes), check if those columns have high Index Selectivity, if the Index Selectivity in some columns is low, it means that the column has few different values, that is, the scan index returns more records for the merge operations that follow it, consuming more CPU and memory. Sometimes, rewriting the query with the UNION statement gives better results than when the server unions the indexes in the index merge.
When you see the index merge in the EXPLAIN statement, review the query and table structure to check if the current design is optimal.
Choose the correct order of columns to index
When our index contains many columns, the order of columns in that index is very important, because in B-tree index, the index will be sorted from the leftmost column to the next columns. Therefore, we often choose the columns with the highest Index Selectivity as the leftmost column, order the columns in descending order of Index Selectivity, so that our overall index has high selectivity.
select count(distinct productVendor)/count(1),
count(distinct productScale)/count(1)
from `classicmodels`.`products_index`;
+----------------------------------------+---------------------------------------+
| count(distinct productVendor)/count(1) | count(distinct productScale)/count(1) |
+----------------------------------------+---------------------------------------+
| 0.2600 | 0.0145 |
+----------------------------------------+---------------------------------------+
In the above example, if we index 2 columns productVendor and productScale, we will usually take productVendor as the leftmost column
alter table `classicmodels`.`products_index` add key (productVendor, productScale);
Some more considerations about the index to pay attention to such as clustered index, covering index, remove redundant, unused indexes, ... I would like to mention in another article.

