
In these early blogs, I will only write about the most basic algorithms when I'm just starting to learn programming. First, let me relearn the basics (because I'm extremely forgetful). Second, for those who are new to programming, you can refer to it. This article will talk about the basic sorting algorithms I learned in school, and also taught myself.
Why do we need sorting algorithms?
Firstly, simply to pass exams at university, learn some Programming Languages, Data Structures and Algorithms, etc., it's easy to be asked these sorts of questions when taking the exam.
Second, element arrangement is usually an intermediate stage, pre-processing data in many problems, processing systems,... to perform larger jobs after it. Since the amount of data in real systems is always very large, we need efficient sorting algorithms to save the cost (time and memory).
Basic examples of applying sorting algorithms
- Sort the list of customers by name in the customer management system.
- Find the median element in , or search for an element with if there is a sorted array.
- The database uses merge sort algorithms to sort data sets when they are too large to load locally into memory.
- Files search, data compression, routes finding.
- Graphic application also use sorting algorithms to arrange layers to render efficiently.
- After finishing the meal, your mother made you wash the dishes. You struggled with dozens of bowls for an hour and now you don't want to waste any more time on those bowls. As it turns out, the remaining job is to arrange the dishes so that they are neat, beautiful, and most of all, quickly so that you can play with your phone. Instinctively for all Asians of average intelligence, you've sorted them out very quickly and stacked them up from small to big chunks, and then you realize you've accidentally applied Counting Sort algorithm.
Basic operations using in the intermediate stages
- Compare 2 elements , return if , otherwise return .
- Swap 2 elements , in Python, it can be performed easily like
a, b = b, a
During the analysis of algorithms, we assume that the above operations take only constant time .
Bubble sort
Bubble sort is a simple and inefficient sort that is taught in almost all algorithm courses because it is quite intuitive. Bubble sort compares each pair of numbers in an array and swaps places if they're out of order. The largest elements will be pushed to the bottom of the array, while the smaller elements will gradually "float" to the top of the array.
Algorithm:
- Compare to , if , swap their positions. Continue doing this with (), (),...
- Repeat this step times.
To make it more intuitive, I give the following descriptive image
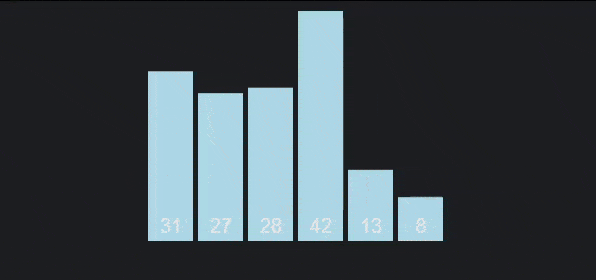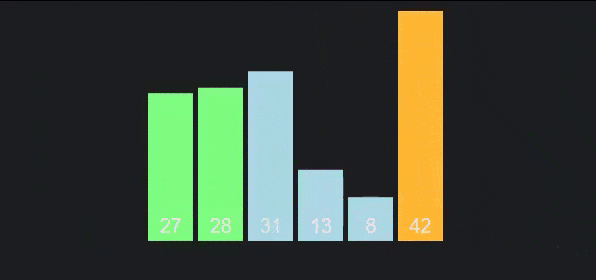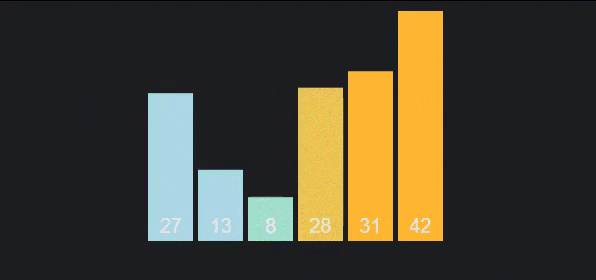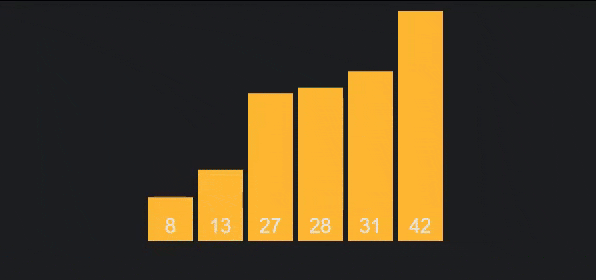
Algorithm analysis:
- Best case: occurs when we apply the algorithm on the sorted array. Then, there will be no swap steps in the first pass, only comparison steps, from which the algorithm will end after this pass. So the time complexity will be . For this reason, bubble sort is also used to check if an array is sorted.
- Worst case: occurs when the array is sorted in reverse, therefore, comparisons and swaps will be performed on the first pass, comparisons and swaps will be performed on the second pass,... Therefore, the total number of comparisons and swaps will be . Time complexity will be .
- Space complexity: .
Python Code
ini_arr = [1, 5, 2, 45, 2, 32, 12, 55, 26, 77, 8]
def bubble_sort(arr):
for i in range(len(arr)):
swapped = False
for j in range(len(arr) - i - 1):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
swapped = True
if not swapped:
return
bubble_sort(ini_arr)
print(ini_arr)
Output
[1, 2, 2, 5, 8, 12, 26, 32, 45, 55, 77]
Insertion sort
Imagine you play card game, when you have the deck in your hand, you have many ways to arrange it depending on your personality. For me, I usually arrange the cards in order from smallest to largest. When I want to arrange a new card into the deck of cards in my hand that is in order, I just insert the card into the appropriate position, and that is also the idea of insertion sort.
Algorithm: With , we will insert into the sorted array by moving the elements greater than of the array to the top and put in the desired position.
To make it more intuitive, I give the following descriptive image
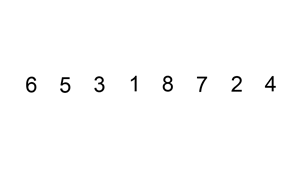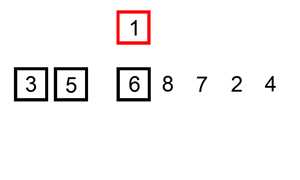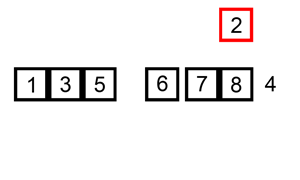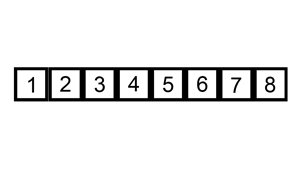
Algorithm analysis:
- Best case: occurs when we apply the algorithm to the sorted array. Then, we only need to iterate over the array, only compare and do not need to perform a swap step at all. So the time complexity will be .
- Worst case: occurs when the array is sorted in reverse, there will be 1 comparison and assignment in the first pass, 2 comparisons and assignment in the second,... Therefore, the total number of operations compare and assign would be . Therefore, time complexity will be .
- Space complexity: .
Python Code
ini_arr = [1, 5, 2, 45, 2, 32, 12, 55, 26, 77, 8]
def insertion_sort(arr):
for key in range(1, len(arr)):
value = arr[key]
j = key - 1
while j >= 0 and value < arr[j]:
arr[j+1] = arr[j]
j -= 1
if key != j+1:
arr[j+1] = value
insertion_sort(ini_arr)
print(ini_arr)
Output
[1, 2, 2, 5, 8, 12, 26, 32, 45, 55, 77]
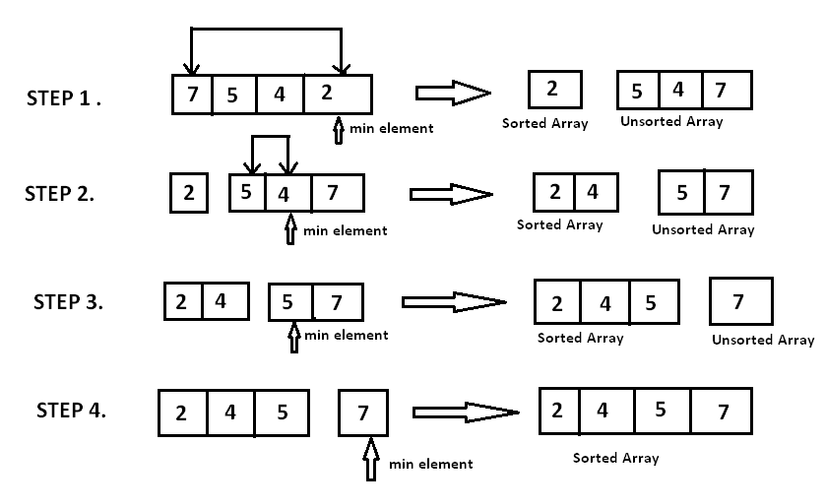
Selection sort
The idea is that we will assume to split our array into 2 parts: sorted subarray and unsorted subarray . At this moment, . We will in turn find the smallest element of , detach and push the element to . The assumption here, that we are not actually creating 2 new sub-arrays, but the operations are performed on the original array.
Algorithm:
- Find the smallest element of .
- Swap the position of that smallest element with the first element of . At this point, we assume in , that smallest element is gone, and now it has been merged into .
I have an image to make the algorithm more intuitive
Algorithm analysis:
- Best case: occurs when applying the algorithm on the sorted array, we only have to compare, not swap positions. So the time complexity will be .
- Worst case: occurs when the above array is sorted in reverse, each time we have to find the smallest element of the subarray . Therefore, the total number of traversals to find the smallest elements will be . Time complexity will be .
- Space complexity: .
Python Code
ini_arr = [1, 5, 2, 45, 2, 32, 12, 55, 26, 77, 8]
def selection_sort(arr):
for i in range(len(arr) - 1):
min_index = i
for j in range(i+1, len(arr)):
if arr[j] < arr[min_index]:
min_index = j
if i != min_index:
arr[min_index], arr[i] = arr[i], arr[min_index]
selection_sort(ini_arr)
print(ini_arr)
Output
[1, 2, 2, 5, 8, 12, 26, 32, 45, 55, 77]
Merge sort
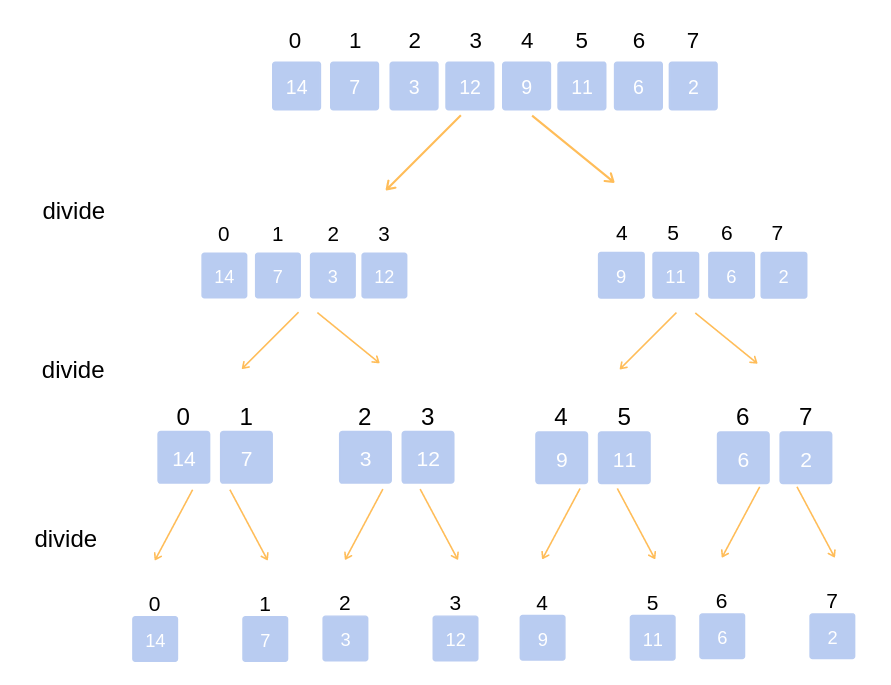
Merge sort is one of the most efficient algorithms. The algorithm works on the principle of divide and conquer, separating the arrays into 2 sub-arrays, respectively, until the sub-arrays have only 1 element left. Then the algorithm "merge" those sub-arrays into a fully sorted array.
Algorithm:
- Divide the original array into 2 sub-arrays, 2 sub-arrays into 4 more sub-arrays,... until we get subarrays, each subarray contains 1 element.
- Merge sub-arrays to create larger arrays sorted in order until we get a single array. That is the sorted array from the original array.
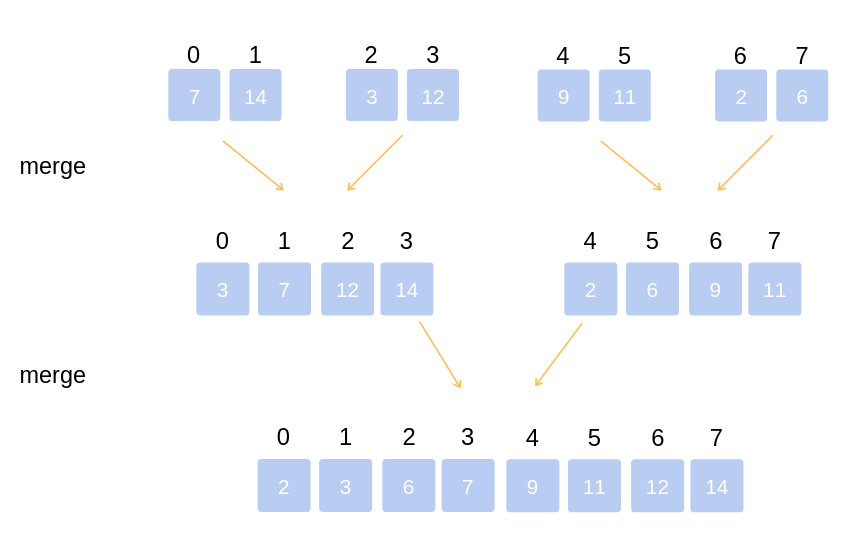
Summarize the algorithm in 1 image
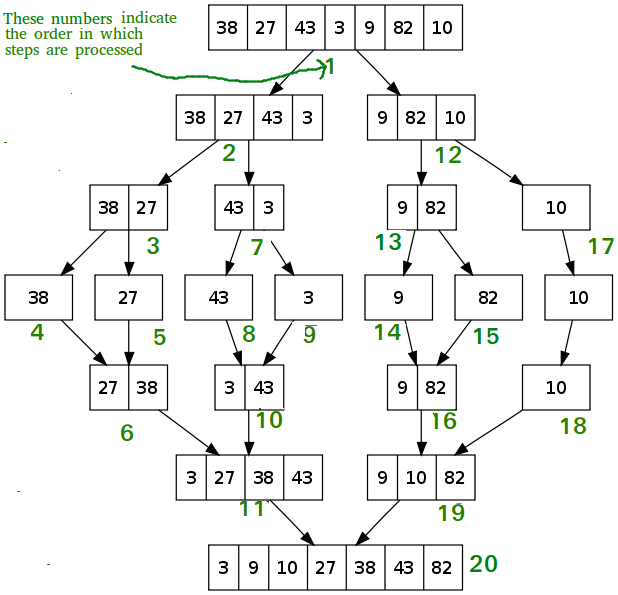
Algorithm analysis:
- Split array: the algorithm will calculate the midpoint of the array by taking the array length and then dividing it by 2, so it takes constant time to split the array into 2 sub-arrays.
- Sorting subarrays: assuming array sorting costs time. So to sort 2 sub-arrays, we spend time.
- Merge 2 subarrays: using the "2-finger" algorithm, each index finger points to the beginning of each subarray. We in turn compare 2 numbers at 2 positions that 2 fingers point to and choose the smaller number to push into the resulting array. Every element in a subarray is pushed in, we move the index finger to the next element of that array. This will make us have to traverse elements, therefore, that costs . Thus, we have the following expression
With base case here is .
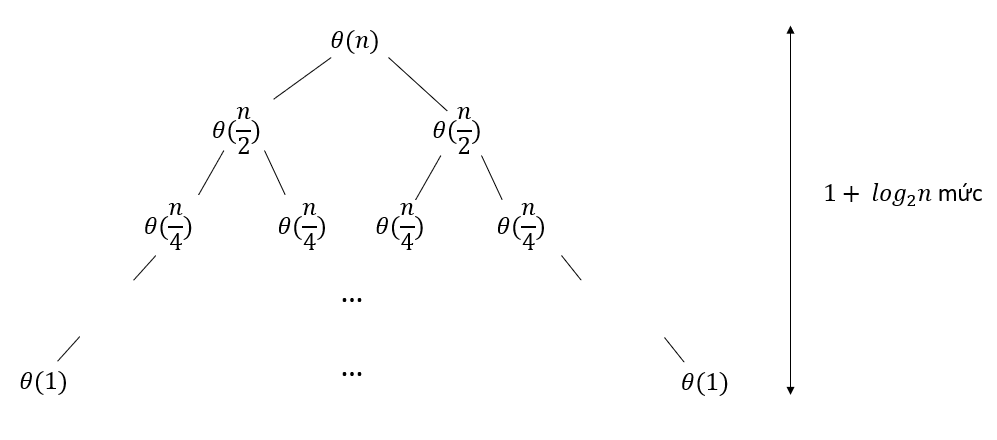
For each tree level, the algorithm executes units of work, there are total levels. Therefore, . Time complexity will be .
- Space complexity: Because in the "merge" step, we have to manually create 2 sub-arrays, each with a number of elements , so the auxiliary memory space will be .
Python Code
import math
ini_arr = [1, 5, 2, 45, 2, 32, 12, 55, 26, 77, 8]
def merge(arr, l, m, r):
n1 = m - l + 1
n2 = r - m
L = []
R = []
for i in range(n1):
L.append(arr[l+i])
for j in range(n2):
R.append(arr[m+j+1])
i = 0
j = 0
k = l
while i < n1 and j < n2:
if L[i] <= R[j]:
arr[k] = L[i]
i += 1
else:
arr[k] = R[j]
j += 1
k += 1
while i < n1:
arr[k] = L[i]
i += 1
k += 1
while j < n2:
arr[k] = R[j]
j += 1
k += 1
def merge_sort(arr, l, r):
if l < r:
m = math.floor(l + (r-l)/2)
merge_sort(arr, l, m)
merge_sort(arr, m+1, r)
merge(arr, l, m, r)
merge_sort(ini_arr, 0 ,len(ini_arr) - 1)
print(ini_arr)
Output
[1, 2, 2, 5, 8, 12, 26, 32, 45, 55, 77]
Heap sort
The heap sort is based on the binary heap data structure.
Binary heap data structure: An array of data can be represented as a binary tree as follows
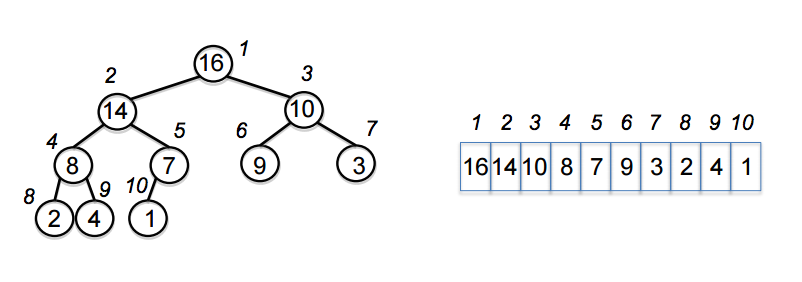
For any node with the corresponding index in the binary tree above
- Parent node of , which is will have the index of .
- Left child node, which is will have the index of .
- Right child node, which is will have the index of .
There are two types of this data structure: max-heap and min-heap.
- In max-heap, we always have . Therefore, the largest element is in the root, and the smallest element is in the leaf.
- In min-heap, we always have . Therefore, the smallest element is in the root, and the largest element is in the leaf.
From there, this sorting algorithm applies max-heap or min-heap (in this article, I will use max-heap) to create an ordered array.
Create a max-heap: called max_heapify I will give a simple example with a 3-element array for added visualization, but with an n-element array it will need to be done in a more general way
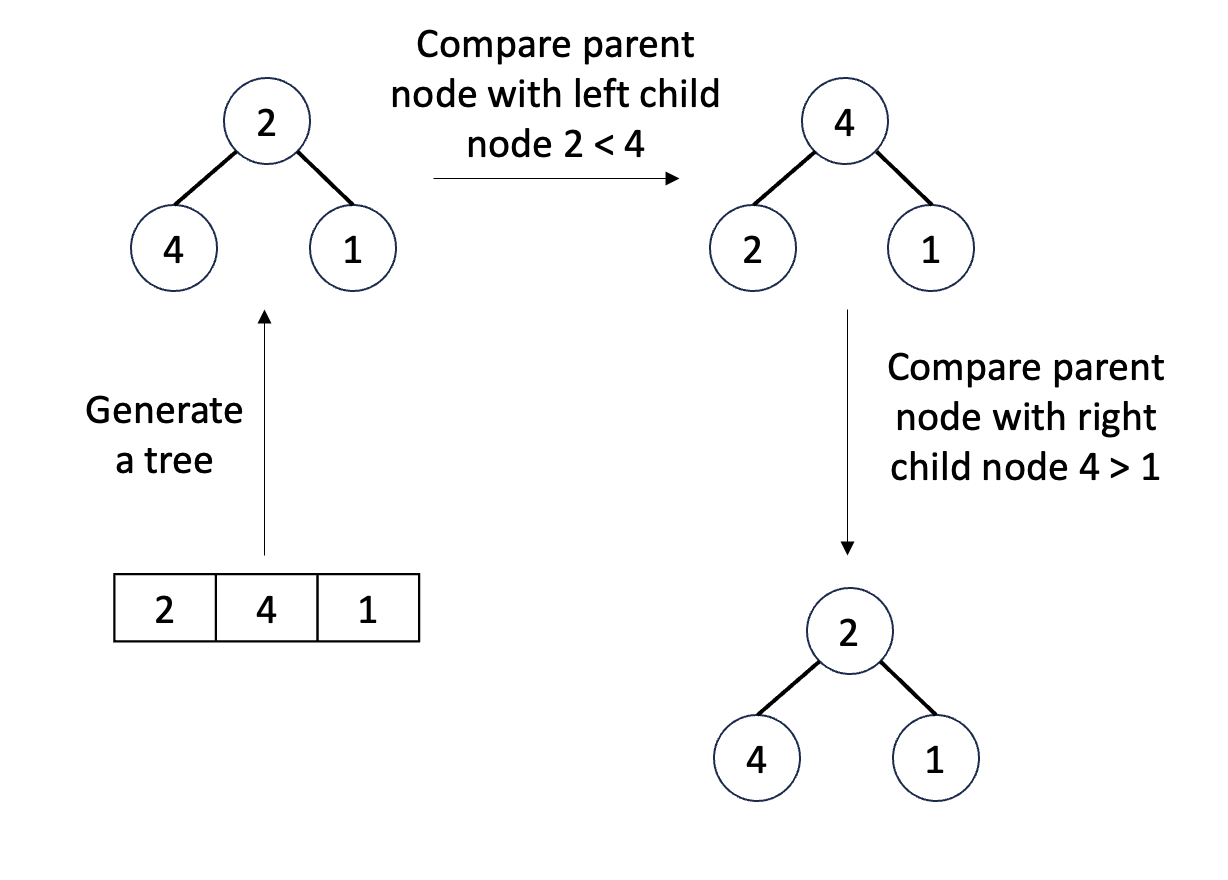
Python code for max_heapify at a node with index , is the length of the array, added as a constraint for the index of child nodes. The algorithm below says that, if the node is at ot in accordance with the max-heap rule, we will max_heapify the tree with the root as that node, and max_heapify the trees with the root being the left and right child nodes of that node.
def max_heapify(arr, length, index):
l = (index + 1) * 2 - 1
r = (index + 1) * 2
largest = index
if l < length and arr[index] < arr[l]:
largest = l
if r < length and arr[largest] < arr[r]:
largest = r
if largest != index:
arr[index], arr[largest] = arr[largest], arr[index]
max_heapify(arr, length, largest)
max_heapify will cost for each node under consideration. Because each time, that node will need to go down 1 level in the tree to be considered, the algorithm will choose the correct branch to go down and it will not backtrack back up. Therefore, the longest path this algorithm can take is from root to a leaf, which is the height of the tree. The height of the binary tree has nodes is .
Algorithm:
- We represent the array and sort the elements to get a max-heap tree. Therefore, the root of this tree (this will correspond to the element with index in the array, for ) will be the largest element.
- We swap the location of root with the last element of the array . At this point, the largest element of the array is in the last index.
- Repeat steps 1 and 2 with the rest of the array ,...
Algorithm analysis: Building a max-heap tree from an unsorted array needs functiohn calls max_heapify, each max_heapify cost time. Thus, the whole algorithm has a time complexity of . However, the heap sort algorithm has an advantage over merge sort in that it only uses temporary memory, while merge sort is . If the memory factor is also important in your system (eg. small memory systems like embedded systems, etc.), you should consider using heap sort rather than merge sort.
Python Code
import math
ini_arr = [1, 5, 2, 45, 2, 32, 12, 55, 26, 77, 8]
def max_heapify(arr, length, index):
l = (index + 1) * 2 - 1
r = (index + 1) * 2
largest = index
if l < length and arr[index] < arr[l]:
largest = l
if r < length and arr[largest] < arr[r]:
largest = r
if largest != index:
arr[index], arr[largest] = arr[largest], arr[index]
max_heapify(arr, length, largest)
def heap_sort(arr):
length = len(arr)
last = math.floor(length / 2)
# Tại đây, chỉ duyệt từ phần tử n/2 đổ về, vì phần tử từ n/2 + 1,..., n đều là leaves. Các leaves đã được thỏa mãn tính chất max-heap
for i in range(last - 1, -1, -1):
max_heapify(arr, length, i)
for i in range(length - 1, 0, -1):
arr[i], arr[0] = arr[0], arr[i]
max_heapify(arr, i, 0)
heap_sort(ini_arr)
print(ini_arr)
Output
[1, 2, 2, 5, 8, 12, 26, 32, 45, 55, 77]
Quick sort
The quick sort algorithm, developed by a British computer scientist Tony Hoare in 1959, uses the principle of divide and conquer to sort an array.
Algorithm:
- Split array:
- Select any element (called pivot), . If we choose a good pivot, our algorithm will run very fast. However, it will be difficult to know which element is considered a good pivot. There are a few common pivot selections:
- Choose a random pivot.
- Select the leftmost or rightmost element.
- Take 3 elements: first, middle, last of the array and pick the median from them.
- Split our array into 2 subparts: consists of elements smaller than , and consists of elements larger than . The image below shows more visually how to divide the array, with pivot always taking the last element
- Select any element (called pivot), . If we choose a good pivot, our algorithm will run very fast. However, it will be difficult to know which element is considered a good pivot. There are a few common pivot selections:
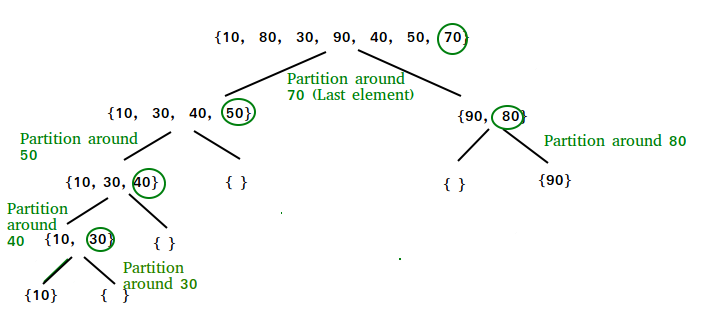
- Conquer: recursively sort the above 2 subsections using quick sort.
- Merge: no need to combine the divided subsections because the final result is already sorted array.
- The complete recursive algorithm:
- Select a pivot. Split array into 2 parts based on pivot.
- Apply quick sort on the smaller half of the pivot.
- Apply quick sort on half larger than pivot.
Algorithm analysis:
With is the number of elements which are smaller than pivot. The time complexity for partitioning process is .
- Best case: occurs when the partitioning algorithm always divides our array into exactly 2 equal or nearly equal parts.
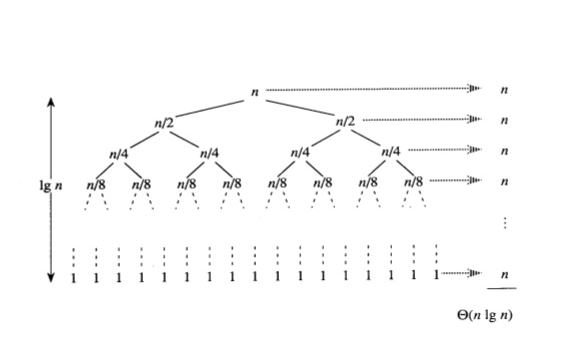
Thus, in the best case, the time complexity will be .
- Worst case: occurs when the partitioning algorithm always chooses the largest or the smallest number as the pivot. If we choose the pivot using the "always pick the last element of the array" strategy, the worst case will happen when the array is sorted in descending order. At this moment
With the base case being then in the worst case, time complexity will be
Although the worst case of quick sort is much slower than other sorting algorithms, in practice the partition loop can be implemented efficiently on almost all data structures, because it contains relatively fewer "constant factors" (operators that require constant time ) than other algorithms, and if two algorithms have the same time complexity , the algorithm with fewer "constant factors" runs faster. Furthermore, the worst case of quick sort will rarely happen. However, with a very large amount of data and stored in external memory, merge sort will be preferred over quick sort.
Python Code
ini_arr = [1, 5, 2, 45, 2, 32, 12, 55, 26, 77, 8]
def partition(arr, l, r):
pointer = l - 1
pivot = arr[r]
for j in range(l, r):
if arr[j] < pivot:
pointer += 1
arr[pointer], arr[j] = arr[j], arr[pointer]
arr[pointer+1], arr[r] = arr[r], arr[pointer+1]
return pointer + 1
def quick_sort(arr, l, r):
if l < r:
pivot_index = partition(arr, l, r)
quick_sort(arr, l, pivot_index - 1)
quick_sort(arr, pivot_index+1, r)
quick_sort(ini_arr, 0, len(ini_arr) - 1)
print(ini_arr)
Output
[1, 2, 2, 5, 8, 12, 26, 32, 45, 55, 77]
Counting sort
An interesting algorithm I learned that even runs at linear time is counting sort. This algorithm is applied almost exclusively to integers, it is difficult or impossible to apply to real numbers.
Algorithm:
- Assume the elements of the original array contains elements with values in the range . Counting sort creates another temporary array to count as array including elements. The element of will contain the number of elements satisfy with .
- From , if we flatten it, we will get an array contains ordered elements. To be more intuitive, I have the following example
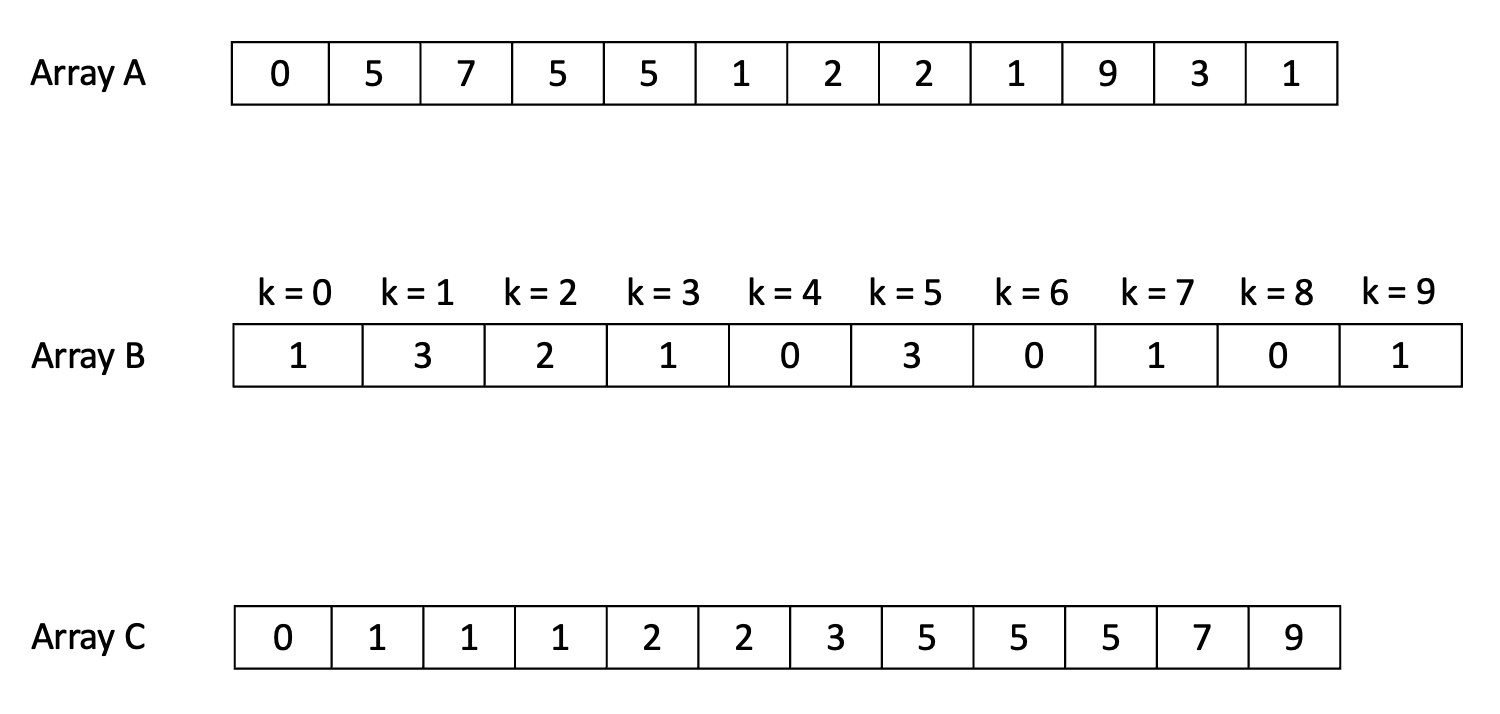
For the case contains negative elements, we find the smallest element of and store that element of at the index of the array (because there cannot exist negative index in an array).
Algorithm analysis:
- Create empty array cost time.
- Calculate the elements of the array based on cost time.
- Flatten to have will cost time.
Total time complexity will be .
This analysis will be clearly written in the comments of the code.
- Space complexity:
Python Code
ini_arr = [-10, -5, -20, -10, -1, -5, 5, 2, 45, 2, 32, 12, 55, 26, 77, 8]
def counting_sort(A):
min_ele = int(min(A))
max_ele = int(max(A))
range_ele = max_ele - min_ele + 1
B = []
# This costs O(k) time
for i in range(range_ele):
B.append(0)
###############################
# This costs O(n) time
for i in range(len(A)):
B[A[i] - min_ele] += 1
###############################
C = []
# We have sum(B)= n = len(A) and append() cost constant time O(1). So this step costs O(n) time
for i in range(range_ele):
for j in range(B[i]):
C.append(i + min_ele)
###############################
# ----> In total, the algorithm costs O(n+k) time complexity
return C
print(counting_sort(ini_arr))
Output
[-20, -10, -10, -5, -5, -1, 2, 2, 5, 8, 12, 26, 32, 45, 55, 77]
Counting sort comments:
- As we saw above, counting sort has a time complexity and a space complexity , o counting sort is very efficient when the range of the input data is small, not much larger than (or when is quite small). For example, if is large, about , then time complexity and space complexity will be , that is very bad.
- Counting sort can also be suitable for problems where the elements of the array are another data structure, but that data structure must have a is the integer to represent each object in that data structure.
- Counting sort is also a subroutine for a more powerful algorithm called Radix sort, a sort algorithm that runs at linear time with values greater than in counting sort, which is (constant power of ).
- As mentioned in the introduction, you arrange the bowls in order from small to large, accumulating the number of bowls by size into blocks one by one. That is using counting sort. As the example below, equal numbers are cubed by color.

Additional notes
Sorting algorithms are quite interesting. One of the things that makes people feel the most comfortable is seeing their bedrooms organized and clean, the same is true when we look at other things arranged. The website about animations of sorting algorithms that give you a sense of satisfaction and relaxation.

