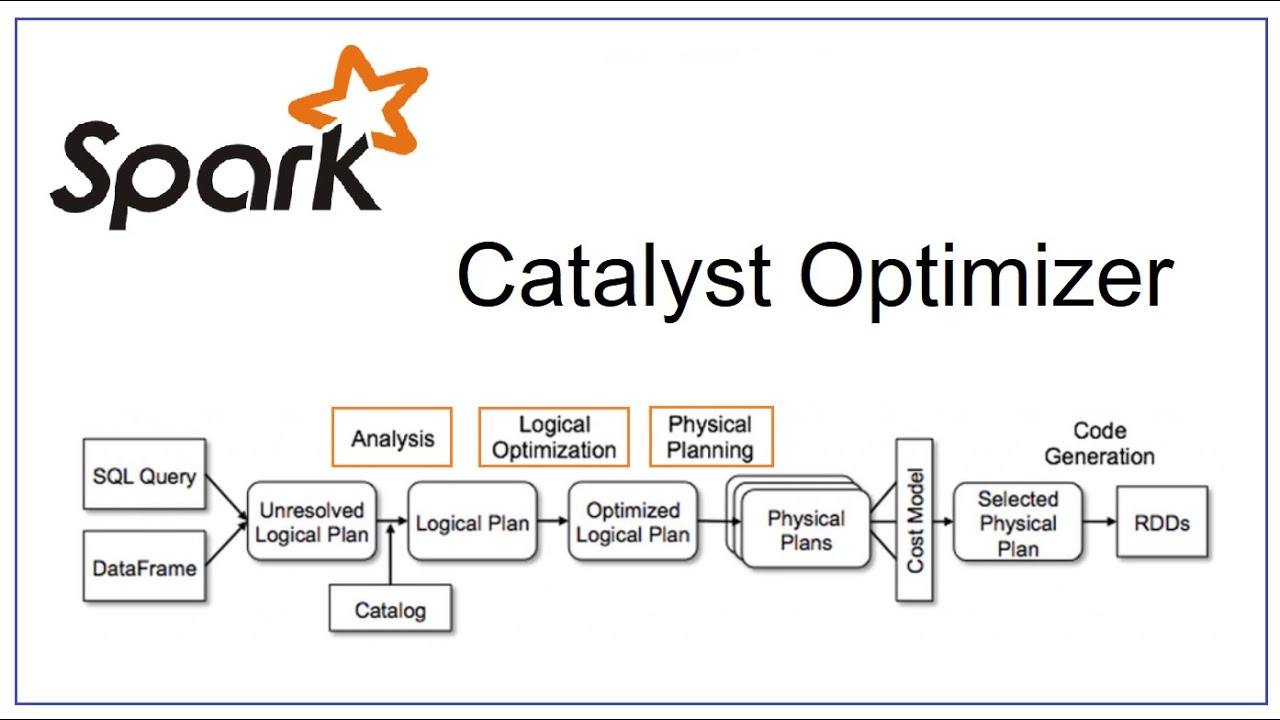
Spark catalyst optimizer is located at the core of Spark SQL with the purpose of optimizing structured queries expressed in SQL or through DataFrame/Dataset APIs, minimizing application running time and costs. When using Spark, often people see the catalyst optimizer as a black box, when we assume that it works mysteriously without really caring what happens inside it. In this article, I will go in depth of its logic, its components, and how the Spark session extension participates to change the Catalyst's plans.