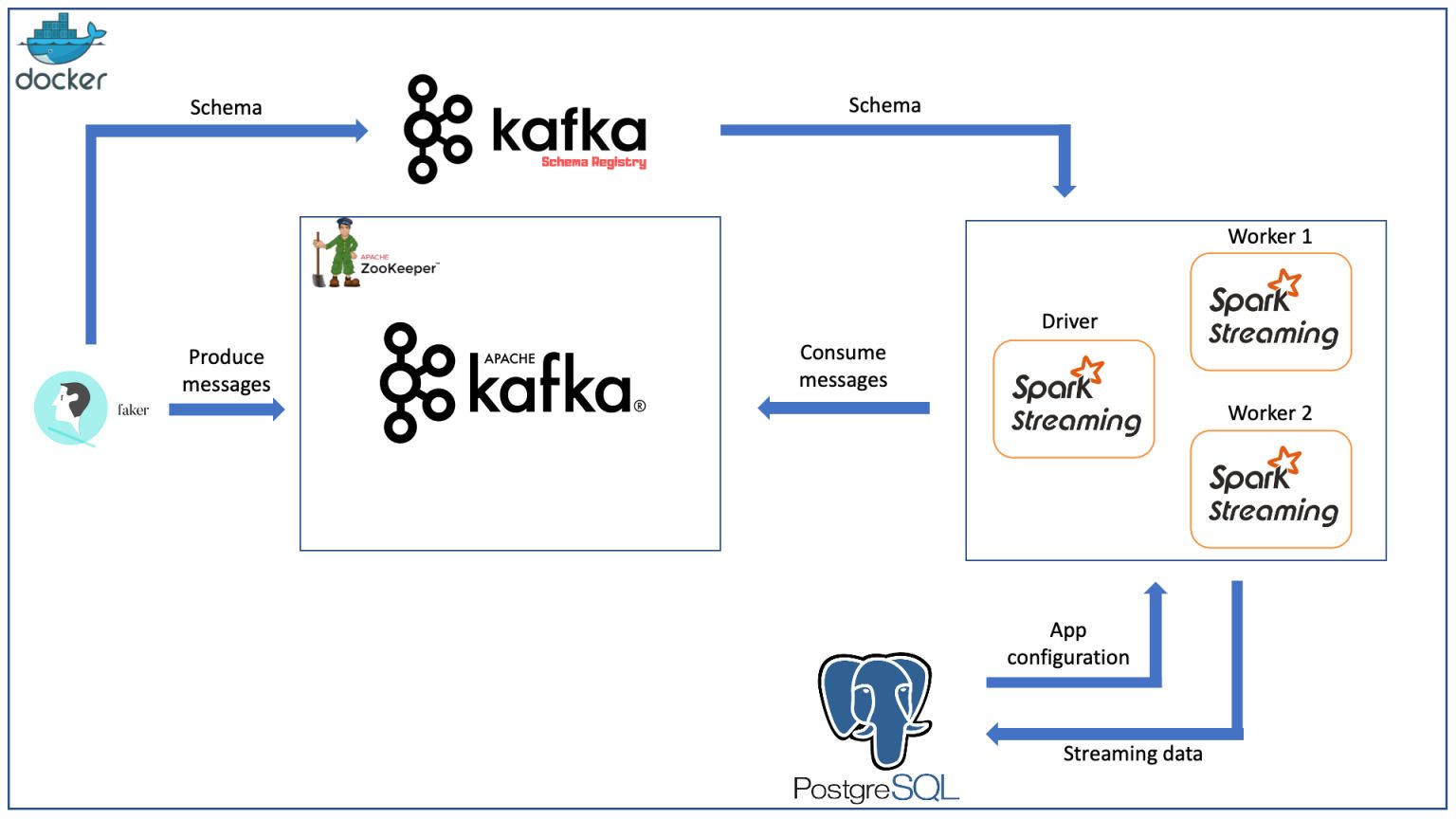
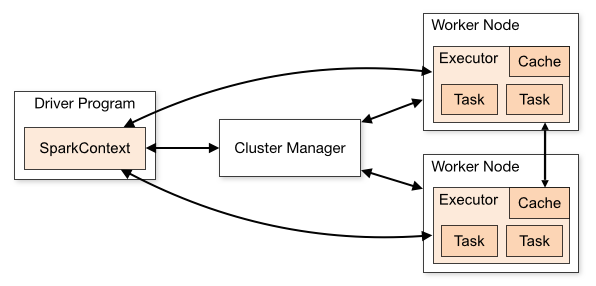
Hello everyone, recently, I did some research in MySQL because I think whoever doing data engineering should go in-depth with a certain relational database. Once you get a deep understanding of one RDBMS, you can easily learn the other RDBMS since they have many similarities. For the next few blogs, I will have a series about MySQL, and this is the first article.
MySQL series - MySQL Architecture Overview
· 5 min read

Data Engineer